Tuesday, December 1, 2015
Wednesday, November 25, 2015
MATLAB on OSX
Install the old, Apple provided Java SE 6
Make sure JDK 8 is not installed like so
https://support.apple.com/kb/DL1572?locale=en_US
http://www.mathworks.com/matlabcentral/answers/160070-how-do-i-install-r2013a-student-on-yosemite
https://discussions.apple.com/thread/6163798
Make sure JDK 8 is not installed like so
sudo rm -rf /Library/Java/JavaVirtualMachines/jdk<version>.jdk
sudo rm -rf /Library/PreferencePanes/JavaControlPanel.prefPane
sudo rm -rf /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin
sudo rm -rf /Library/LaunchAgents/com.oracle.java.Java-Updater.plist
sudo rm -rf /Library/PrivilegedHelperTools/com.oracle.java.JavaUpdateHelper
sudo rm -rf /Library/LaunchDaemons/com.oracle.java.JavaUpdateHelper.plist
sudo rm -rf /Library/Preferences/com.oracle.java.Helper-Tool.plisthttps://support.apple.com/kb/DL1572?locale=en_US
http://www.mathworks.com/matlabcentral/answers/160070-how-do-i-install-r2013a-student-on-yosemite
https://discussions.apple.com/thread/6163798
Wednesday, August 19, 2015
VNC Tidbits
vncconfig -iconic &
after server is running on a machine to copy and paste out of VNC terminal
Thursday, July 9, 2015
Add git-gui alias for OSX and brew
Add the following line to ~/.bashrc (version subject to change...)
alias gui="sh -c '/usr/local/Cellar/git/2.3.3/libexec/git-core/git-gui'"
alias gui="sh -c '/usr/local/Cellar/git/2.3.3/libexec/git-core/git-gui'"
Wednesday, April 29, 2015

Sunday, April 19, 2015
IFT6266 Summary
In summary, convolutional VAE and batch normalization seem very useful for fast training of VAE models for image data. Unfortunately there appear to be some Theano related issues with the current implementation of batch normalization, which cause the generated computation graph to ~100x slower for the convolutional version than the feedforward version. Eventually the convolutional version should be very efficient, but for now training times of two or three days are not as useful as the 40 minute training times for the feedforward model.
Semi-supervised VAE is also a very promising avenue for learning better generative models, but implementing the model proposed earlier will take time after the course is over. For now, all the code remains posted at https://github.com/kastnerkyle/ift6266h15 , with improvements to both batch normalization and the convolutional model, and soon semi-supervised VAE.
Semi-supervised VAE is also a very promising avenue for learning better generative models, but implementing the model proposed earlier will take time after the course is over. For now, all the code remains posted at https://github.com/kastnerkyle/ift6266h15 , with improvements to both batch normalization and the convolutional model, and soon semi-supervised VAE.
Tuesday, April 14, 2015
IFT6266 Week 11
Adding rescaling rmsprop with nesterov momentum as the optimizer, instead of sgd with nesterov, has proved to be quite valuable. The feedforward model now trains to "good sample" level within about 45 minutes. The current code is here https://github.com/kastnerkyle/ift6266h15
However, the convolutional model takes 3 days! Something might be wrong...
Original:

Samples from the feedforward model:

Reconstructions from feedforward:
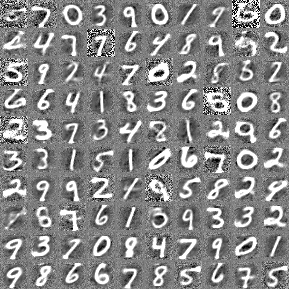
Original:

Samples from the convolutional model:

Reconstructions from the convolutional model:

However, the convolutional model takes 3 days! Something might be wrong...
Original:
Samples from the feedforward model:
Reconstructions from feedforward:
Original:
Samples from the convolutional model:
Reconstructions from the convolutional model:
Sunday, April 12, 2015
IFT6266 Week 10
This week was largely spent on presentations and getting ready for the last push before April 20th.
Semi supervised (feedforward) VAE will probably be my last topic. The model I hope to use will take the label and concatenate following the code layer which should allow the model to mix this information in during reconstruction. This means that it should possible to sample the code layer and clamp the label to "ground truth" or chosen label, and get examples of the generated class. It should also be possible to feed in unlabeled X and generate Y'. The cost would then be nll + KL + indicator {labeled, notlabeled} * softmax error.
This can be seen as two separate models that share parameters - a standard classifier from X to Y, predicting Y', and a VAE from X to X' where the sampled code layer is partially clamped. This may require adding another KL term, but I hope it will be sufficient to train the softmax penalty using the available labeled data. In the limit of no labels, this should devolve back into standard VAE with KL evaluated on only *part* of the code layer, which may not be ideal. The softmax parameters of the white box may be more of a problem than I am anticipating.
This model departs somewhat from others in the literature (to my knowledge), so there may be a flaw in this plan.
Diagram:
Semi supervised (feedforward) VAE will probably be my last topic. The model I hope to use will take the label and concatenate following the code layer which should allow the model to mix this information in during reconstruction. This means that it should possible to sample the code layer and clamp the label to "ground truth" or chosen label, and get examples of the generated class. It should also be possible to feed in unlabeled X and generate Y'. The cost would then be nll + KL + indicator {labeled, notlabeled} * softmax error.
This can be seen as two separate models that share parameters - a standard classifier from X to Y, predicting Y', and a VAE from X to X' where the sampled code layer is partially clamped. This may require adding another KL term, but I hope it will be sufficient to train the softmax penalty using the available labeled data. In the limit of no labels, this should devolve back into standard VAE with KL evaluated on only *part* of the code layer, which may not be ideal. The softmax parameters of the white box may be more of a problem than I am anticipating.
This model departs somewhat from others in the literature (to my knowledge), so there may be a flaw in this plan.
Diagram:

Saturday, April 4, 2015
IFT6266 Week 9
This week I recoded a basic feedforward VAE, using batch normalization at every layer. There are still some small plumbing issues related to calculating fixed point statistics but I am hoping to solve those soon.


Random samples from Z:

Adding BN to VAE appears to make it much easier to train. I am currently using standard SGD with nesterov momentum, and it is working quite well. Before adding batch normalization no-one (to my knowledge) had been able to train a VAE using MLP encoders and decoders, on real valued MNIST, with a Gaussian prior. A tiny niche to be sure, but one I am happy to have succeeded in!
Source image:
Reconstructed:
Random samples from Z:
I am currently finalizing a convolutional VAE (as seen in my early posts) with the addition of batch normalization. If this network performs as well as before, I plan to extend to semi-supervised learning either with the basic VAE or the convolutional one to finish the course.
Thursday, March 26, 2015
Wednesday, March 25, 2015
IFT6266 Week 8
After looking at batch normalization, I really think that the gamma and beta terms are correcting for the bias in the minibatch estimates of mean and variance, but have not confirmed. I am also toying with ideas along the same lines as Julian, except using reinforcement learning to choose the optimal minibatch that gives the largest expected reduction in training or validation error rather than controlling hyperparameters as he is doing. One possible option would be something like CACLA for real valued things, and LSPI for "switches".
Batch normalization (and nesterov momentum) seem to help. After only 11 epochs, an ~50% smaller network is able to reach equivalent validation performance.
Epoch 11
Train Accuracy 0.874000
Valid Accuracy 0.802000
Loss 0.364031
The code for the batch normalization layer is here:
https://github.com/kastnerkyle/ift6266h15/blob/master/normalized_convnet.py#L46
With the same sized network as before, things stay pretty consistently around 80% but begin to massively overfit. The best validation scores, with .95 nesterov momentum are:
Epoch 10
Train Accuracy 0.875050
Valid Accuracy 0.813800
Loss 0.351992
Epoch 36
Train Accuracy 0.967650
Valid Accuracy 0.815800
Epoch 96
Train Accuracy 0.992100
Valid Accuracy 0.822000
I next plan to try batch normalization on fully connected and convolutional VAE. First trying with MNIST, then LFW, then probably cats and dogs. It would be nice to try to either a) mess with batch normalization and do it properly *or* simplify the equations somehow b) do some reinforcement learning like Julian is doing, but on the minibatch selection process. However, time is short!
Batch normalization (and nesterov momentum) seem to help. After only 11 epochs, an ~50% smaller network is able to reach equivalent validation performance.
Epoch 11
Train Accuracy 0.874000
Valid Accuracy 0.802000
Loss 0.364031
The code for the batch normalization layer is here:
https://github.com/kastnerkyle/ift6266h15/blob/master/normalized_convnet.py#L46
With the same sized network as before, things stay pretty consistently around 80% but begin to massively overfit. The best validation scores, with .95 nesterov momentum are:
Epoch 10
Train Accuracy 0.875050
Valid Accuracy 0.813800
Loss 0.351992
Epoch 36
Train Accuracy 0.967650
Valid Accuracy 0.815800
Epoch 96
Train Accuracy 0.992100
Valid Accuracy 0.822000
I next plan to try batch normalization on fully connected and convolutional VAE. First trying with MNIST, then LFW, then probably cats and dogs. It would be nice to try to either a) mess with batch normalization and do it properly *or* simplify the equations somehow b) do some reinforcement learning like Julian is doing, but on the minibatch selection process. However, time is short!
Thursday, March 12, 2015
IFT6266 Week 7
With a 50% probability of introducing a horizontal flip, the network gets very close to passing the 80% threshold with early stopping.
Epoch 93
Train Accuracy 0.951350
Valid Accuracy 0.794200
Epoch 93
Train Accuracy 0.951350
Valid Accuracy 0.794200
With the addition of per pixel mean and standard deviation normalization the network successfully gets over 80% validation accuracy (barely)!
Epoch 74
Train Accuracy 0.878000
Valid Accuracy 0.803800
The working version of the network can be seen here:
https://github.com/kastnerkyle/ift6266h15/blob/master/convnet.py
Note that addition of ZCA did not seem to help in this case!
Train Accuracy 0.878000
Valid Accuracy 0.803800
The working version of the network can be seen here:
https://github.com/kastnerkyle/ift6266h15/blob/master/convnet.py
Note that addition of ZCA did not seem to help in this case!
With these changes, I will move on to implementing other models/ideas. First up, batch normalization, then spatially sparse convolution and possibly fractional maxpooling.
Wednesday, March 11, 2015
IFT6266 Week 6
The network has been working this entire time, there was just bug in my prediction accuracy percentage printing! See this snippet for an example
In [3]: import numpy as np
In [4]: a = np.array([1., 2., 3., 4., 5.])
In [5]: b = np.array([[1.], [2.], [3.], [4.], [5.]])
In [3]: import numpy as np
In [4]: a = np.array([1., 2., 3., 4., 5.])
In [5]: b = np.array([[1.], [2.], [3.], [4.], [5.]])
In [6]: a
Out[6]: array([ 1., 2., 3., 4., 5.])
Out[6]: array([ 1., 2., 3., 4., 5.])
In [7]: b
Out[7]:
array([[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
In [8]: (a == b).mean()
Out[8]: 0.20000000000000001
The correct way to print these is (a.flatten() == b.flatten()).astype('float32').mean()
For a task with 2 classes, this will always give ~50% accuracy but the number will change slightly due to small changes in the prediction!
It is an obvious bug in hindsight, but it took a long time to find. Now after 100 epochs, the results are as follows:
Epoch 99
Train Accuracy 0.982200
Valid Accuracy 0.751000
Loss 0.021493
Out[7]:
array([[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
In [8]: (a == b).mean()
Out[8]: 0.20000000000000001
The correct way to print these is (a.flatten() == b.flatten()).astype('float32').mean()
For a task with 2 classes, this will always give ~50% accuracy but the number will change slightly due to small changes in the prediction!
It is an obvious bug in hindsight, but it took a long time to find. Now after 100 epochs, the results are as follows:
Epoch 99
Train Accuracy 0.982200
Valid Accuracy 0.751000
Loss 0.021493
The general network architecture is:
Resize all images to 64x64, then crop the center 48x48
No flipping, random subcrops, or anything
32 kernels, 4x4 with 2x2 pooling and 2x2 strides
64 kernels, 2x2 with 2x2 pooling
128 kernels, 2x2 with 2x2 pooling
512x128 fully-connected
128x64 fully connected
64x2 fully connected
All initialized uniformly [-0.1, 0.1]
ReLU activations at every layer
Softmax cost
I plan to try:
Adding random horizontal flipping
ZCA with 0.1 bias
dropout or batch normalization
PReLU
dark knowledge / knowledge distillation
Monday, March 2, 2015
Install Konsole/gnome-terminal for better Vim experience in OS X
Go to the App Store and install Xcode
Next, go to https://www.macports.org to download and install MacPorts
After this do
For gnome terminal:
sudo port install gnome-terminal
otherwise
sudo port install konsole
For both apps, you will also need
sudo port install xorg-server
In the Applications file under MacPorts, there should be an X11 app. Launch this before trying to launch either gnome-terminal or console.
Next, go to https://www.macports.org to download and install MacPorts
After this do
For gnome terminal:
sudo port install gnome-terminal
otherwise
sudo port install konsole
For both apps, you will also need
sudo port install xorg-server
In the Applications file under MacPorts, there should be an X11 app. Launch this before trying to launch either gnome-terminal or console.
Sunday, February 15, 2015
IFT6266 Week 5
The convent has gone no farther this week since massively overfitting, but I had a few interesting discussions with Roland about computationally efficient pooling which should be useful once I solve my current issues.
I also got the convolutional VAE working for MNIST. If I can get a good run for CIFAR10 it might also be useful to slap a one or two layer MLP on the hidden space representation to see if that gets above 80% for cats and dogs. If not it would also be fun to train on the dataset itself, folding in all the data and then finetune for prediction. This is a sidetrack from "the list" but could be fruitful.
Here are some samples from the ConvVAE on MNIST (also a link to the current code here https://gist.github.com/kastnerkyle/f3f67424adda343fef40/9b6bf8c66c112d0ca8eb87babb717930a7d42913 ).

I also got the convolutional VAE working for MNIST. If I can get a good run for CIFAR10 it might also be useful to slap a one or two layer MLP on the hidden space representation to see if that gets above 80% for cats and dogs. If not it would also be fun to train on the dataset itself, folding in all the data and then finetune for prediction. This is a sidetrack from "the list" but could be fruitful.
Here are some samples from the ConvVAE on MNIST (also a link to the current code here https://gist.github.com/kastnerkyle/f3f67424adda343fef40/9b6bf8c66c112d0ca8eb87babb717930a7d42913 ).
Monday, February 9, 2015
IFT6266 Week 4
I got the convolutional-deconvolutional VAE working as a standalone script now - training it on LFW to see the results. The code can be found here: https://gist.github.com/kastnerkyle/f3f67424adda343fef40
I have also completed coding a convnet in pure theano which heavily overfits the dogs and cats data. See convnet.py here: https://github.com/kastnerkyle/ift6266h15
Current training stats:
Epoch 272
Train Accuracy 0.993350
Valid Accuracy 0.501600
Loss 0.002335
The architecture is:
load in data as color and resize all to 48x48
1000 epochs, batch size 128
SGD with 0.01 learning rate, no momentum
layer 1 - 10 filters, 3x3 kernel, 2x2 max pool, relu
layer 2 - 10 filters, 3x3 kernel, 1x1 max pool, relu
layer 3 - 10 filters, 3x3 kernel, 1x1 max pool, relu
layer 4 - fully connected 3610x100, relu
layer 5 - softmax
The next step is quite obviously to add dropout. With this much overfitting I am hopeful that this architecture can get me above 80%. Other things to potentially add include ZCA preprocessing, maxout instead of relu, network-in-network, inception layers, and more. Also considering bumping the default image size to 64x64, random subcrops, image flipping, and other preprocessing tricks.
Once above 80%, I want to experiment with some of the "special sauce" from Dr. Ben Graham - fractional max pooling and spatially sparse convolution. His minibatch dropout also seems quite nice!
I have also completed coding a convnet in pure theano which heavily overfits the dogs and cats data. See convnet.py here: https://github.com/kastnerkyle/ift6266h15
Current training stats:
Epoch 272
Train Accuracy 0.993350
Valid Accuracy 0.501600
Loss 0.002335
The architecture is:
load in data as color and resize all to 48x48
1000 epochs, batch size 128
SGD with 0.01 learning rate, no momentum
layer 1 - 10 filters, 3x3 kernel, 2x2 max pool, relu
layer 2 - 10 filters, 3x3 kernel, 1x1 max pool, relu
layer 3 - 10 filters, 3x3 kernel, 1x1 max pool, relu
layer 4 - fully connected 3610x100, relu
layer 5 - softmax
The next step is quite obviously to add dropout. With this much overfitting I am hopeful that this architecture can get me above 80%. Other things to potentially add include ZCA preprocessing, maxout instead of relu, network-in-network, inception layers, and more. Also considering bumping the default image size to 64x64, random subcrops, image flipping, and other preprocessing tricks.
Once above 80%, I want to experiment with some of the "special sauce" from Dr. Ben Graham - fractional max pooling and spatially sparse convolution. His minibatch dropout also seems quite nice!
Sunday, February 1, 2015
IFT6266 Week 3
Alec Radford shared some very interesting results on LFW using Convolutional VAE (https://t.co/mfoK8hcop5 and https://twitter.com/AlecRad/status/560200349441880065). I have been working to convert his code into something more generally useable, as his version (https://gist.github.com/Newmu/a56d5446416f5ad2bbac) depends on other local code from Indico.
This *probably* won't be the thing that gets above our 80% baseline, but it would be cool to get it working for another dataset. It may also be interesting for other projects since we know convolutional nets can work well for sound.
This *probably* won't be the thing that gets above our 80% baseline, but it would be cool to get it working for another dataset. It may also be interesting for other projects since we know convolutional nets can work well for sound.
Friday, January 23, 2015
IFT6266 Week 2
Test Vincent Dumoulin's dataset (https://github.com/vdumoulin/ift6266h15/tree/dataset/code/pylearn2/datasets) and get a baseline with a simple convnet or fully connected net.
Monday, January 12, 2015
IFT6266 Week 1
Current plans:
GoogleNet (almost done)
OxfordNet
DeepCNet/Deep Sparse Network (Benjamin Graham)
Deep Scattering Networks (Mallat)
Convolutional Kernel Networks (Mairal)
Disjunctive Normal Networks (this paper)
GoogleNet (almost done)
OxfordNet
DeepCNet/Deep Sparse Network (Benjamin Graham)
Deep Scattering Networks (Mallat)
Convolutional Kernel Networks (Mairal)
Disjunctive Normal Networks (this paper)
Subscribe to:
Posts (Atom)