Wednesday, April 29, 2015

Sunday, April 19, 2015
IFT6266 Summary
In summary, convolutional VAE and batch normalization seem very useful for fast training of VAE models for image data. Unfortunately there appear to be some Theano related issues with the current implementation of batch normalization, which cause the generated computation graph to ~100x slower for the convolutional version than the feedforward version. Eventually the convolutional version should be very efficient, but for now training times of two or three days are not as useful as the 40 minute training times for the feedforward model.
Semi-supervised VAE is also a very promising avenue for learning better generative models, but implementing the model proposed earlier will take time after the course is over. For now, all the code remains posted at https://github.com/kastnerkyle/ift6266h15 , with improvements to both batch normalization and the convolutional model, and soon semi-supervised VAE.
Semi-supervised VAE is also a very promising avenue for learning better generative models, but implementing the model proposed earlier will take time after the course is over. For now, all the code remains posted at https://github.com/kastnerkyle/ift6266h15 , with improvements to both batch normalization and the convolutional model, and soon semi-supervised VAE.
Tuesday, April 14, 2015
IFT6266 Week 11
Adding rescaling rmsprop with nesterov momentum as the optimizer, instead of sgd with nesterov, has proved to be quite valuable. The feedforward model now trains to "good sample" level within about 45 minutes. The current code is here https://github.com/kastnerkyle/ift6266h15
However, the convolutional model takes 3 days! Something might be wrong...
Original:

Samples from the feedforward model:

Reconstructions from feedforward:
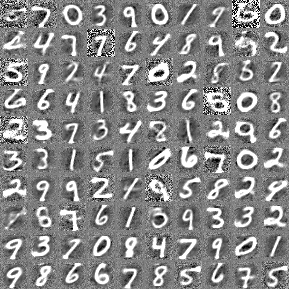
Original:

Samples from the convolutional model:

Reconstructions from the convolutional model:

However, the convolutional model takes 3 days! Something might be wrong...
Original:
Samples from the feedforward model:
Reconstructions from feedforward:
Original:
Samples from the convolutional model:
Reconstructions from the convolutional model:
Sunday, April 12, 2015
IFT6266 Week 10
This week was largely spent on presentations and getting ready for the last push before April 20th.
Semi supervised (feedforward) VAE will probably be my last topic. The model I hope to use will take the label and concatenate following the code layer which should allow the model to mix this information in during reconstruction. This means that it should possible to sample the code layer and clamp the label to "ground truth" or chosen label, and get examples of the generated class. It should also be possible to feed in unlabeled X and generate Y'. The cost would then be nll + KL + indicator {labeled, notlabeled} * softmax error.
This can be seen as two separate models that share parameters - a standard classifier from X to Y, predicting Y', and a VAE from X to X' where the sampled code layer is partially clamped. This may require adding another KL term, but I hope it will be sufficient to train the softmax penalty using the available labeled data. In the limit of no labels, this should devolve back into standard VAE with KL evaluated on only *part* of the code layer, which may not be ideal. The softmax parameters of the white box may be more of a problem than I am anticipating.
This model departs somewhat from others in the literature (to my knowledge), so there may be a flaw in this plan.
Diagram:
Semi supervised (feedforward) VAE will probably be my last topic. The model I hope to use will take the label and concatenate following the code layer which should allow the model to mix this information in during reconstruction. This means that it should possible to sample the code layer and clamp the label to "ground truth" or chosen label, and get examples of the generated class. It should also be possible to feed in unlabeled X and generate Y'. The cost would then be nll + KL + indicator {labeled, notlabeled} * softmax error.
This can be seen as two separate models that share parameters - a standard classifier from X to Y, predicting Y', and a VAE from X to X' where the sampled code layer is partially clamped. This may require adding another KL term, but I hope it will be sufficient to train the softmax penalty using the available labeled data. In the limit of no labels, this should devolve back into standard VAE with KL evaluated on only *part* of the code layer, which may not be ideal. The softmax parameters of the white box may be more of a problem than I am anticipating.
This model departs somewhat from others in the literature (to my knowledge), so there may be a flaw in this plan.
Diagram:

Saturday, April 4, 2015
IFT6266 Week 9
This week I recoded a basic feedforward VAE, using batch normalization at every layer. There are still some small plumbing issues related to calculating fixed point statistics but I am hoping to solve those soon.


Random samples from Z:

Adding BN to VAE appears to make it much easier to train. I am currently using standard SGD with nesterov momentum, and it is working quite well. Before adding batch normalization no-one (to my knowledge) had been able to train a VAE using MLP encoders and decoders, on real valued MNIST, with a Gaussian prior. A tiny niche to be sure, but one I am happy to have succeeded in!
Source image:
Reconstructed:
Random samples from Z:
I am currently finalizing a convolutional VAE (as seen in my early posts) with the addition of batch normalization. If this network performs as well as before, I plan to extend to semi-supervised learning either with the basic VAE or the convolutional one to finish the course.
Subscribe to:
Comments (Atom)